最近在筹备大数据竞赛,在训练的时候出现了挺多问题,现在统一总结一下
出现的问题
首先,新版IDEA不能从正常的创建项目哪里创建Maven项目(官方的打包方法为sbt,所以正在逐渐淘汰Maven)
但是训练时候依旧需要使用Maven去构建项目,所以经查资料创建方法如下
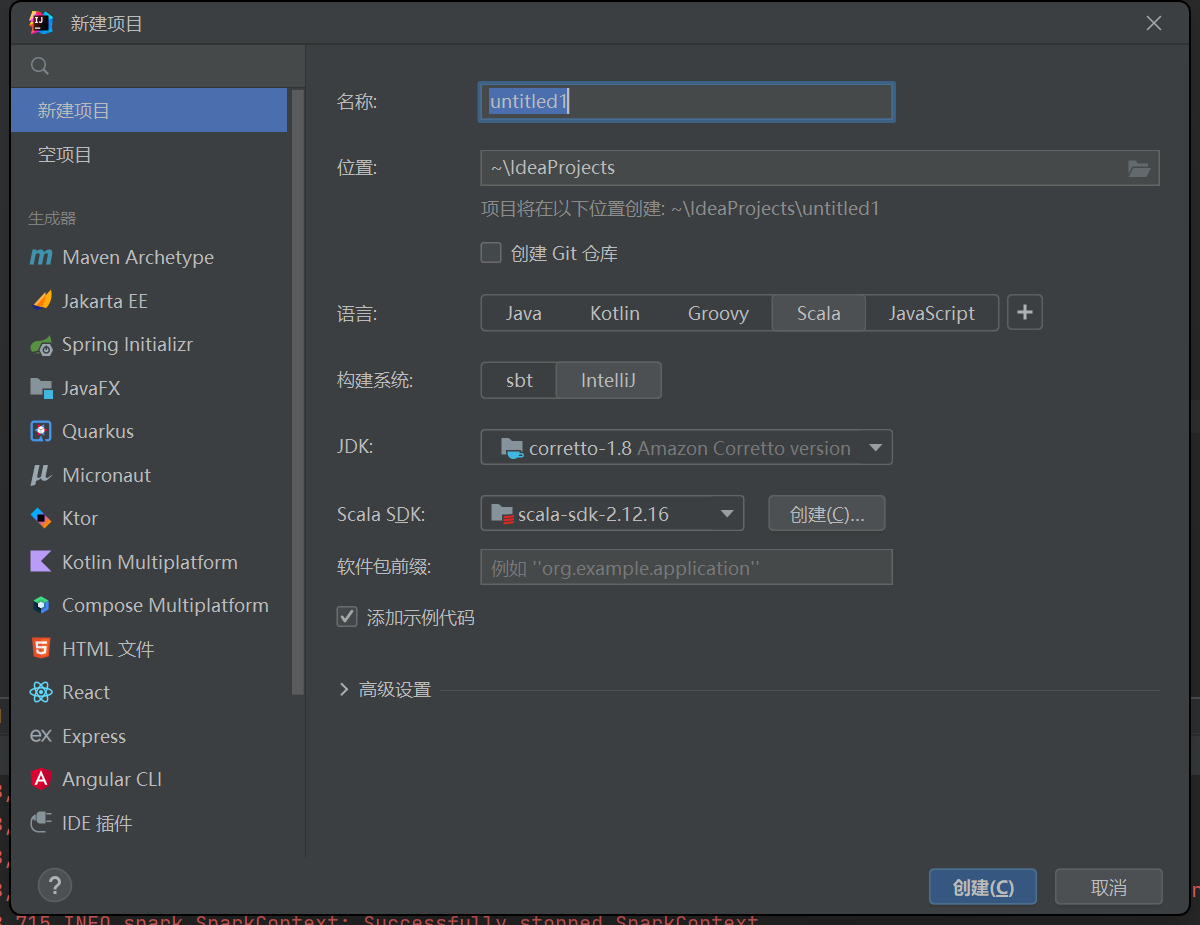
1.首先创建一个Scala项目,构建系统选择Intellij,选择创建。
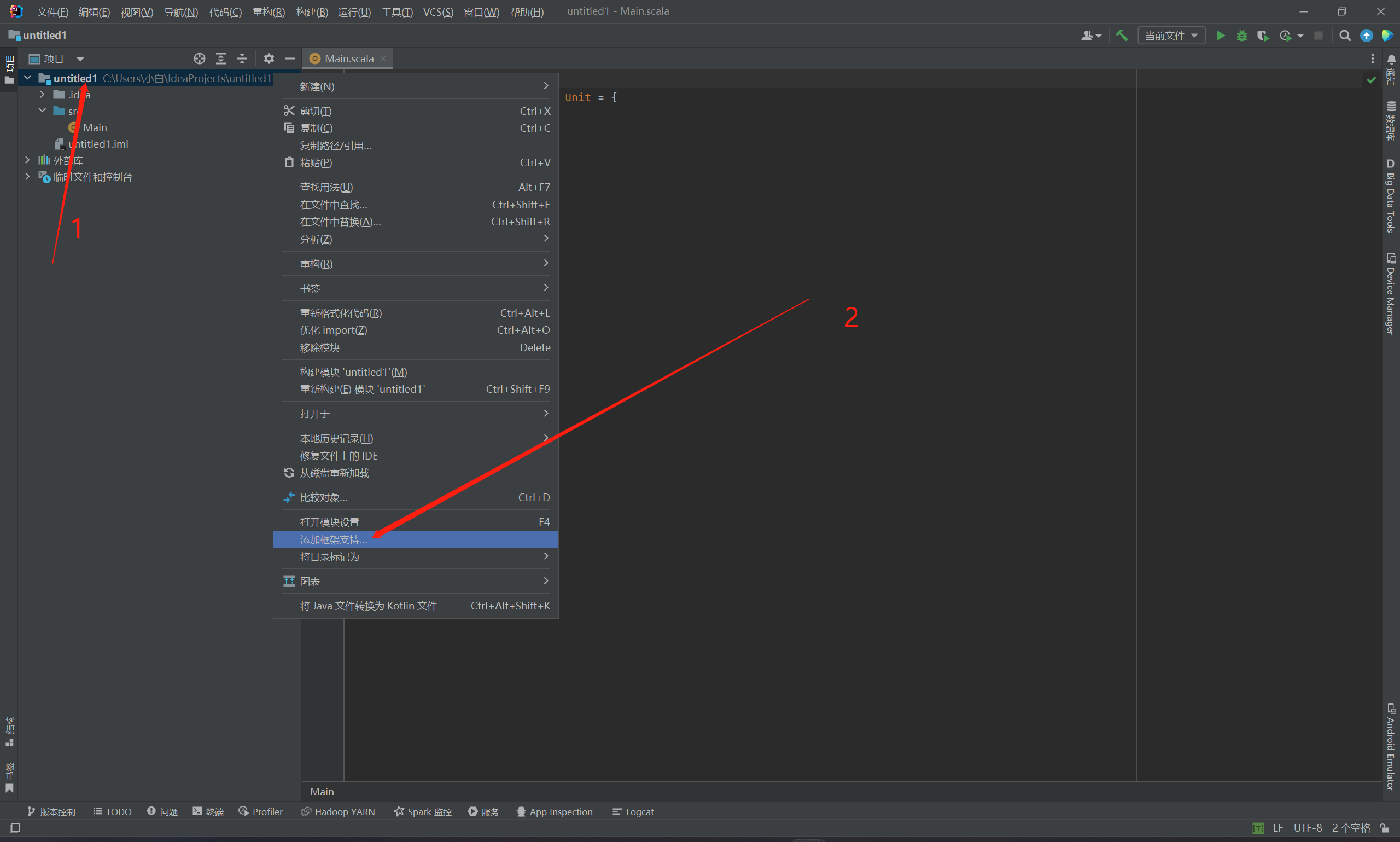
2.右击该项目,选择添加框架支持
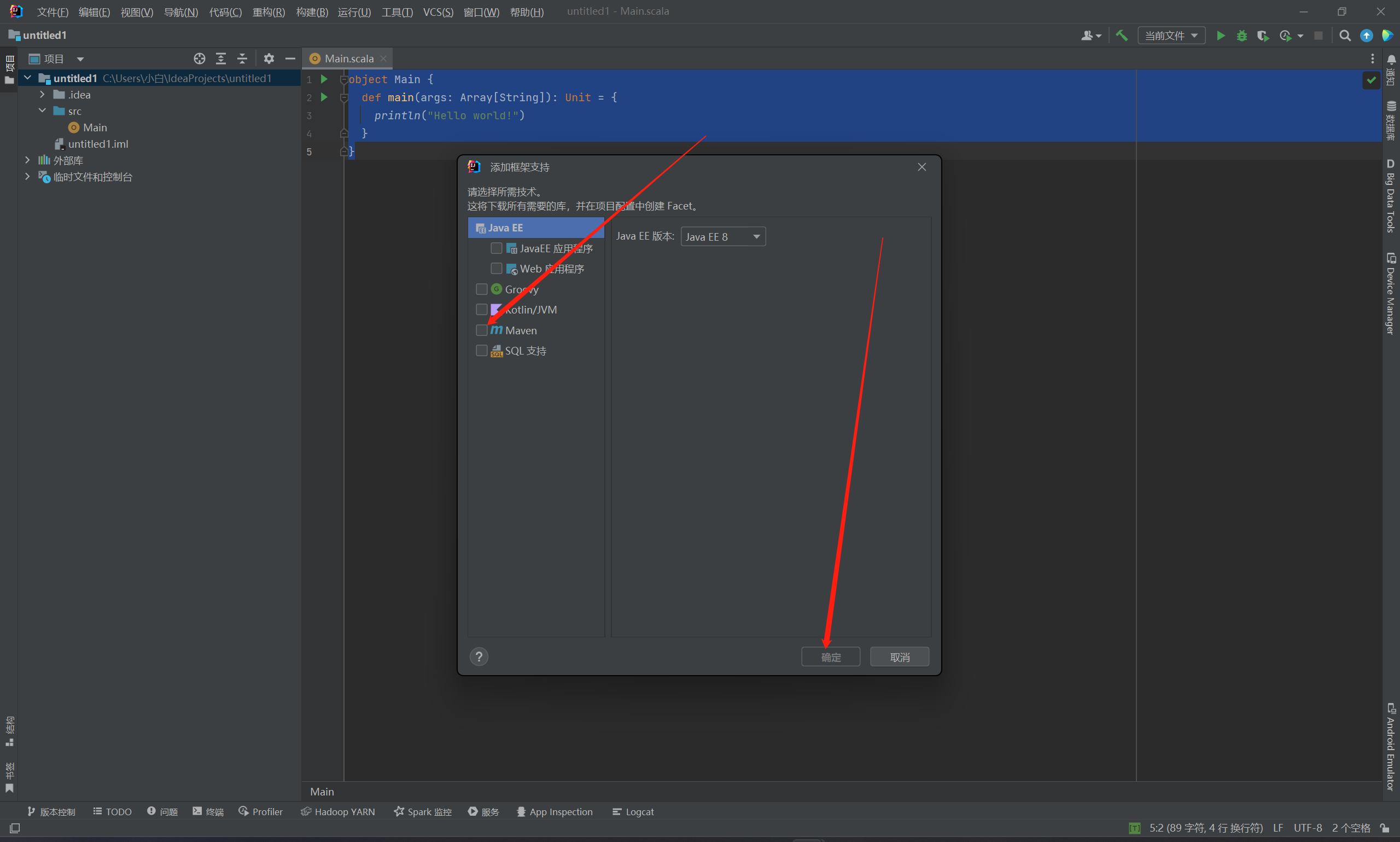
3.勾选Maven,点击确定
4.此时已经创建好pom.xml文件了
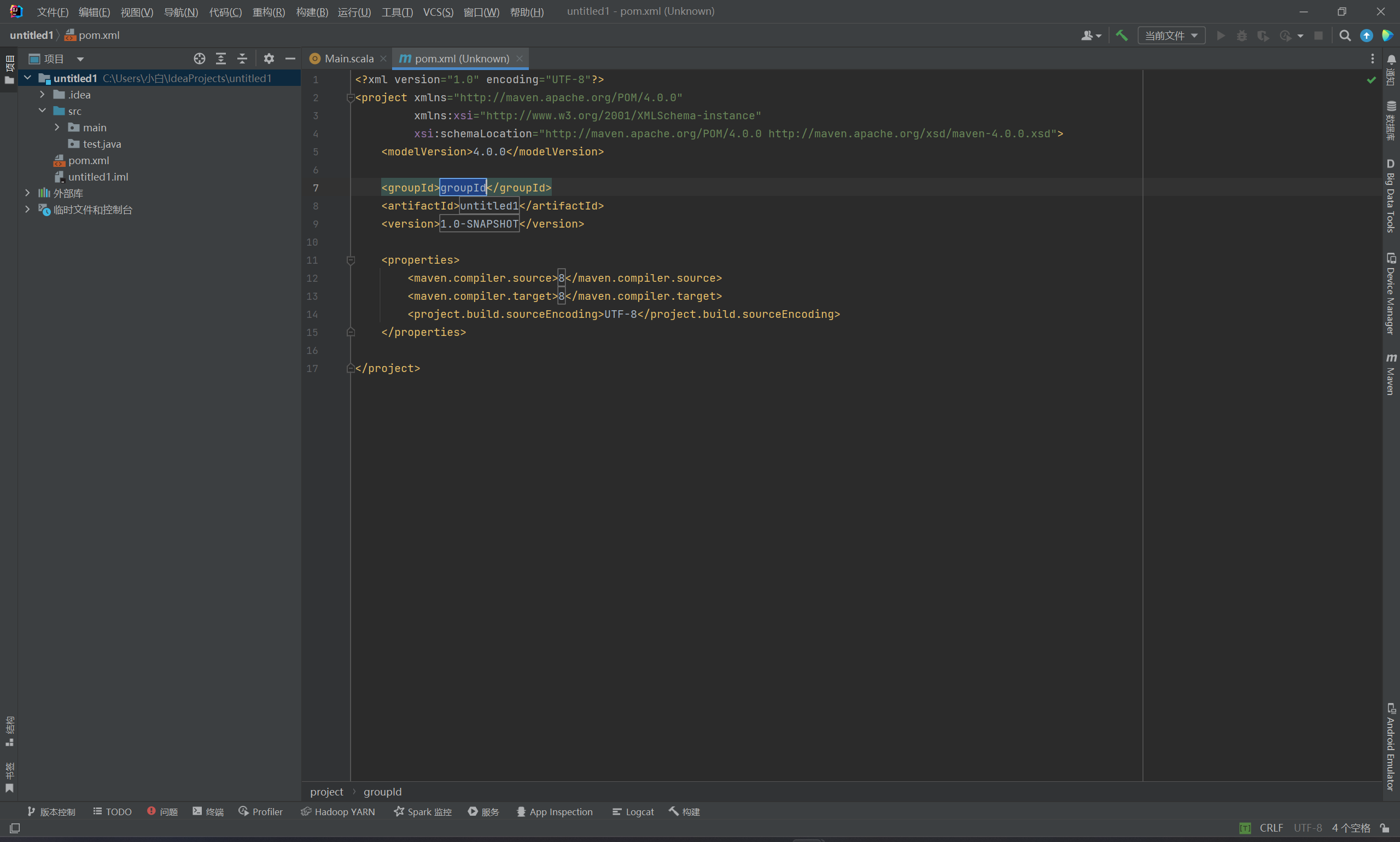
这时就可以添加对应的依赖了
拉取对应的依赖
依赖文件如下
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>top.smallway</groupId>
<artifactId>sparkapp</artifactId>
<version>1.0</version>
<properties>
<scala.version>2.12.16</scala.version>
</properties>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.32</version>
</dependency>
<!-- spark-hive-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- hive-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>com.github.housepower</groupId>
<artifactId>clickhouse-integration-spark_2.12</artifactId>
<version>2.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>此时重新拉取Maven即可
编写Scala代码EltUtil.scala类
import org.apache.spark.sql._
import org.apache.spark.sql.jdbc.{ClickHouseDialect, JdbcDialects}
// ELT工具类
object EltUtil {
// extract from mysql
/**
* @param spark SparkSession实例
* @param jdbcMap 要加载的JDBC配置项
*
* @return 返回一个DataFrame(Dataset[Row])
*
*/
def extractFromJDBC(spark: SparkSession, jdbcMap:Map[String,String]): Dataset[Row] = {
// 读取JDBC数据源,创建DataFrame
val df = spark
.read
.format("jdbc")
.options(jdbcMap)
.load()
// 返回
df
}
// load to hive
/**
* @param spark
* @param df 要装载到Hive中的DataFrame
* @param db 要装载到的Hive数据库
* @param tb 要装载到的Hive ODS表
* @param partitionColumn 指定分区列
*
* @return unit
*/
def loadToHive(spark: SparkSession, df:Dataset[Row], hiveMap: Map[String,String]):Unit = {
val database = hiveMap("db") // 要写入的数据库
val table = hiveMap("tb") // 要写入的数据表
val partitionColumn = hiveMap.get("partitionColumn") // 分区列
spark.sql(s"use $database") // 打开指定数据库,这里使用了字符串插值
// 有的表需要分区,有的不需要。这里使用模式匹配来分别处理
partitionColumn match{
case Some(column) =>
df.write
.format("parquet")
.mode("overwrite") // 覆盖
.partitionBy(column) // 指定分区
.saveAsTable(table)
case None =>
df.write
.format("parquet")
.mode("overwrite") // 覆盖
.saveAsTable(table) // saveAsTable()方法:会将DataFrame数据保存到Hive表中
}
}
// 增量写入方法
def appendToHive(spark: SparkSession, df:Dataset[Row], hiveMap: Map[String,String]):Unit = {
val database = hiveMap("db") // 要写入的数据库
val table = hiveMap("tb") // 要写入的数据表
val partitionColumn = hiveMap.get("partitionColumn") // 分区列
spark.sql(s"use $database") // 打开指定数据库,这里使用了字符串插值
// 有的表需要分区,有的不需要。这里使用模式匹配来分别处理
partitionColumn match{
case Some(column) =>
df.write
.format("parquet")
.mode("append") // 追加
.partitionBy(column) // 指定分区
.saveAsTable(table)
case None =>
df.write
.format("parquet")
.mode("append") // 追加
.saveAsTable(table) // saveAsTable()方法:会将DataFrame数据保存到Hive表中
}
}
// 定义一个函数,用来将分析结果导出到mysql中
/**
*
* @param db 目标数据表
* @param df 分析结果集
*/
import org.apache.spark.sql._
import java.util.Properties
def exportToMysql(df:Dataset[Row], tb:String) = {
val DB_URL= "jdbc:mysql://localhost:3306/shtd_result?useSSL=false" // 数据库连接url,请将localhost替换为服务器所在IP
// 下面创建一个prop 变量用来保存JDBC 连接参数
val props = new Properties()
props.put("user", "root") // 表示用户名是root
props.put("password", "admin") // 表示密码是hadoop
props.put("driver","com.mysql.jdbc.Driver") // 表示驱动程序
df.write.mode("overwrite").jdbc(DB_URL, tb, props)
}
// 定义一个函数,用来将分析结果导出到clickhouse中
/**
*
* @param db 目标数据表(形式:db.tb)
* @param df 分析结果集
*/
def exportToClickHouse(df:Dataset[Row], table:String) = {
// 注册ClickHouseDialect
JdbcDialects.registerDialect(ClickHouseDialect)
// clickhouse驱动程序和连接信息
val ckDriver = "com.github.housepower.jdbc.ClickHouseDriver" // 驱动程序
val ckUrl = "jdbc:clickhouse://localhost:9000" // 数据库连接url,请将localhost替换为服务器所在IP
val ckUser = "default"
val ckPassword = ""
// 写出
try {
val props = new java.util.Properties
props.put("driver", ckDriver)
props.put("user", ckUser)
props.put("password", ckPassword)
df.write
.mode("append")
.option("batchsize", "10000")
.option("isolationLevel", "NONE")
.option("numPartitions", "1")
.jdbc(ckUrl, table, props)
} catch {
case e:Exception =>
println("catch and ignore!")
println(e)
}
}
}在主方法中调用即可
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.lit
object spark {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("sparkapp")
.enableHiveSupport()
.getOrCreate()
val stock_customer_info_sql = "select * from customer_inf where modified_time <= '2022-08-20 23:59:59'"
val jdbcMap = Map(
"url" -> "jdbc:mysql://localhost/database",
"user" -> "user",
"password" -> "password",
"query" -> stock_customer_info_sql,
)
val dataDF = EltUtil.extractFromJDBC(spark, jdbcMap)
val df12 = dataDF.withColumn("etl_date", lit("20221123"))
val hiveMap = Map(
"db" -> "Hive数据库",
"tb" -> "Hive数据库中的表",
"partitionColumn" -> "列名"
)
EltUtil.loadToHive(spark, df12, hiveMap)
spark.table("Hive数据库.表名").show()
}
}